
Felhasznált technológiák: Jenkins 2, Maven 3.3.9, Nexus 2.14, SonarQube 6.3
Az alábbi cikkben egy általam összerakott egyedi megoldást szeretnék bemutatni, ami lehetővé teszi a Jenkins build szám és a maven verziószámok egységes használatát. Remélem mindenki számára hasznos információkat tartalmaz majd ez a bejegyzés. :)
Az alábbi cikkben egy általam összerakott egyedi megoldást szeretnék bemutatni, ami lehetővé teszi a Jenkins build szám és a maven verziószámok egységes használatát. Remélem mindenki számára hasznos információkat tartalmaz majd ez a bejegyzés. :)
Az erőforrásaimat mostanság eléggé lekötik az ALM és DevOps szemlélet gyakorlatba való átültetésének lehetőségei, ezért a blogolásra kicsit kevesebb időm jutott, de ami késik nem múlik :) Az elmúlt időszakban több Continuous Integration projekt is sikeresen záródott, így kellő tapasztalat halmozódott fel az újabb irányok és igények implementálásához is. A mostani cikkemben arról fogok írni, hogy a Jenkins 2 pipeline-t miként integráltam össze a maven verzió kezelésével, de előtte egy kis visszatekintéssel kezdjünk.
Jenkins 1 esetén amikor egy pipeline-t akartunk definiálni, akkor a Build Pipeline vagy a Delivery Pipeline pluginra támaszkodhattunk és a pipeline minden lépését egy-egy külön job-ban tudtuk meghatározni és triggerekkel összekötve építettük fel a láncot. Nem beszélve arról, hogy minden lépéshez egy külön job-ot kellett létrehozni, sok helyen könnyen elrontható volt a pipeline és időigényes is volt az összerakása. Egyszóval valóban megérett egy újragondolásra.


Ezekből a tapasztalatokból született meg a Jenkins 2, ami beépítve támogatja a groovy szkripttel létrehozható pipeline mechanizmust, azaz 1 job-on belül a teljes pipeline-t megírhatjuk, ami a gyakorlatban nagyon hatékony implementációt teszt lehetővé. A Blue Ocen UI plugin segítségével pedig egy modern felületet varázsolhatunk a pipeline köré. Létrehoztam egy pipeline-t ami a következő lépéseket tartalmazza: Build, Unit Test, Store Artifact, Code Coverage, Static Code Check, Deploy és Performance Test.


A build gombra kattinva elindul a pipleline, természetesen a folyamat indítható ütemezetten (pl. minden nap éjfélkor) vagy fejlesztő kommit hatására is, azáltal hogy a Jenkins poll-ozza az SCM-et.
A Build fázisban Maven segítségével buildelődik a forráskód és létrejönnek a telepíthető build termékek (ear, war, jar), majd a Unit Test fázisban lefutnak a JUnit alapú tesztek. Ezután elérkezünk a Store Artifact fázishoz, ahol is egy artifact repositoryban, esetünkben Nexus-ban eltárolódnak a build termékek
Amennyiben a pipeline indításakor a snapshot-ot választottuk ki, a build termékek a snapshot repositoryban fognak eltárolódni, a groupid, artifactid és a verziószámnak megfelelő könyvtár struktúrában. Ahogy az alábbi ábrán is látható a Jenkins build szám megegyezik a snapshot verzióval (0.0.13-SNAPSHOT) és snapshot sorszámával (3), ami esetünkben a 0.0.13-SNAPSHOT-3.

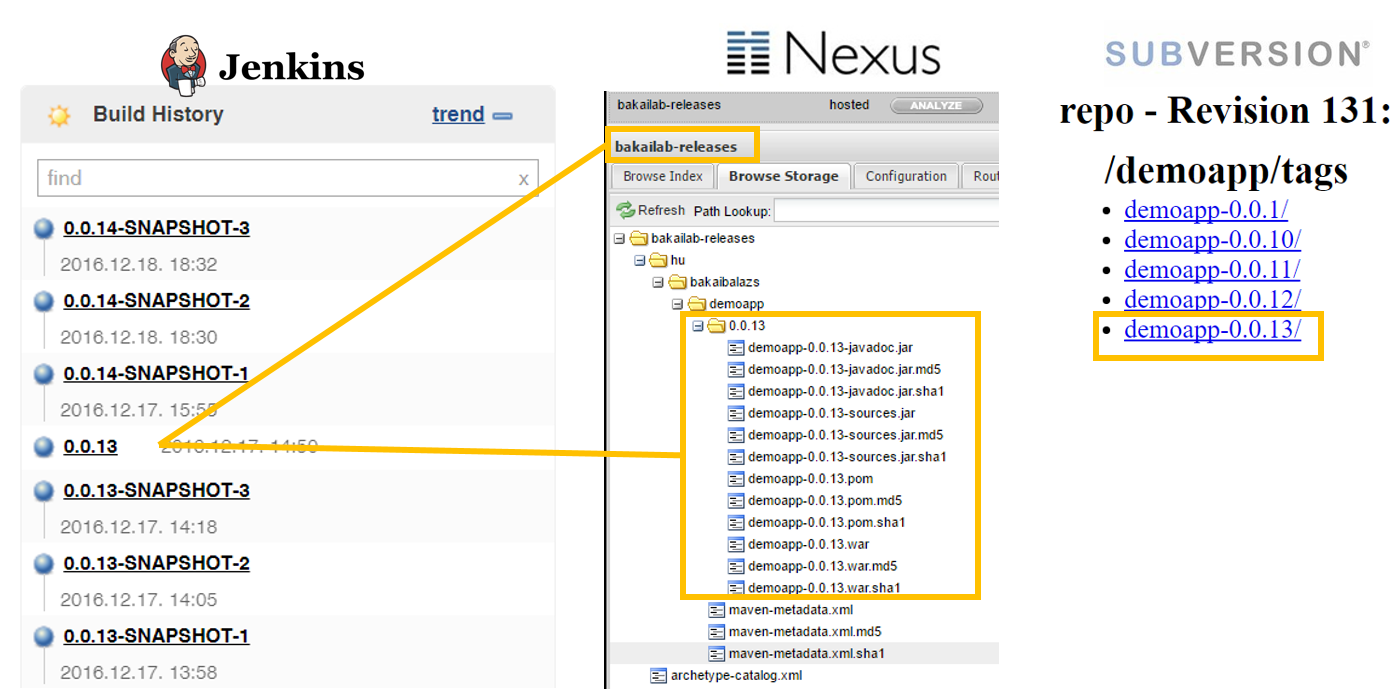
Ha a pipeline indításakor a release-t választjuk ki, a build termékek a release repositoryban fognak eltárolódni és taggelődik a forráskód bázis is, azaz ehhez az állapothoz a későbbiekben bármikor visszatérhetünk. Release készítésekor egyébként a release:prepre és release:perform fog lefutni. Látható, hogy release készítés után a következő snapshot verzió egy inkrementált vagy az általunk megadott sorszámot kapja majd.



A maven verziózásnál 2 típust különböztetünk meg, a SNAPSHOT (fejlesztés alatti) és a RELEASE (kiadható) állapotokat. Ezért a pipeline indításakor is kiválaszthatjuk, hogy snapshot vagy release pipeline-t kívánunk indítani, továbbá release választása esetén opcionálisan megadhatjuk azt is, hogy mi legyen a következő snapshot verziószám, amennyiben el akarnánk térni az alapértelmezettől.

A build gombra kattinva elindul a pipleline, természetesen a folyamat indítható ütemezetten (pl. minden nap éjfélkor) vagy fejlesztő kommit hatására is, azáltal hogy a Jenkins poll-ozza az SCM-et.
A Build fázisban Maven segítségével buildelődik a forráskód és létrejönnek a telepíthető build termékek (ear, war, jar), majd a Unit Test fázisban lefutnak a JUnit alapú tesztek. Ezután elérkezünk a Store Artifact fázishoz, ahol is egy artifact repositoryban, esetünkben Nexus-ban eltárolódnak a build termékek
Amennyiben a pipeline indításakor a snapshot-ot választottuk ki, a build termékek a snapshot repositoryban fognak eltárolódni, a groupid, artifactid és a verziószámnak megfelelő könyvtár struktúrában. Ahogy az alábbi ábrán is látható a Jenkins build szám megegyezik a snapshot verzióval (0.0.13-SNAPSHOT) és snapshot sorszámával (3), ami esetünkben a 0.0.13-SNAPSHOT-3.

Ha a pipeline indításakor a release-t választjuk ki, a build termékek a release repositoryban fognak eltárolódni és taggelődik a forráskód bázis is, azaz ehhez az állapothoz a későbbiekben bármikor visszatérhetünk. Release készítésekor egyébként a release:prepre és release:perform fog lefutni. Látható, hogy release készítés után a következő snapshot verzió egy inkrementált vagy az általunk megadott sorszámot kapja majd.
A pipeline következő 2 fázisa a kód lefedettség mérés és a statikus kód ellenőrzés párhuzamosan fog futni. A statikus kód ellenőrzéshez a SonarQube eszközt szoktam javasolni, ahova az aktuális verziószám szintén delegálásra kerül, így a mérési eredmények beazonosítása egyértelmű.

A következő lépésben egy szkript automatikusan feltelepíti a tesztkörnyezetre az alkalmazást, majd performancia teszteket futtatunk úgy hogy a dynaTrace a háttérben méri az alkalmazás dinamikus jellemzőit mint például a válaszidőt és a performancia hot spotokat. A mérés lefutása után a dynatrace session és minden eredmény adat (unit teszt, kódlefedettség) a Jenkins eredmény oldalán megtekinthető és bármikor vissza kereshető.
Összefoglalva nézzük meg milyen előnyökkel kecsegtet az így kialakított pipeline:
A végére hagytam egy hasznos lehetőséget, méghozzá egy általam létrehozott Deployer jobot, aminek a segítségével a Nexus repository-ban, egy korábban eltárolt release vagy snapshot app verzió egy gombnyomással telepíthető az általunk kiválaszott környezetre. Ez a kis job nagyon hasznos az élesítések végrehajtásához is, ugyanis a megfelelő jogosultságokkal rendelkező adminisztrátorok gyorsan elvégezhetik ezt a feladatot.


A legközelebbi cikkben a környezetenként eltérő konfiguráció kezelésről és az adatbázis automatizált verziózásáról fogok írni, ami szintén szerves része a kialakított platfromnak.

A következő lépésben egy szkript automatikusan feltelepíti a tesztkörnyezetre az alkalmazást, majd performancia teszteket futtatunk úgy hogy a dynaTrace a háttérben méri az alkalmazás dinamikus jellemzőit mint például a válaszidőt és a performancia hot spotokat. A mérés lefutása után a dynatrace session és minden eredmény adat (unit teszt, kódlefedettség) a Jenkins eredmény oldalán megtekinthető és bármikor vissza kereshető.
Összefoglalva nézzük meg milyen előnyökkel kecsegtet az így kialakított pipeline:
- Jenkins 2 segítségével egy szabványos és hatékony pipeline megvalósítás
- Maven release-elés verziószáma megegyezik a Jenkins build számával
- Ha parancssorból (Jenkins nélkül) futtatjuk a maven release kiadását, akkor sem csúsznak el a verziószámok egy későbbi Jenkins pipeline indításakor
- A verziószám végig kíséri az összes lépést
- A Jenkins eredmény oldalán minden lépés eredmény fájlja és naplói elérhetők


A legközelebbi cikkben a környezetenként eltérő konfiguráció kezelésről és az adatbázis automatizált verziózásáról fogok írni, ami szintén szerves része a kialakított platfromnak.
































